
- Что такое данные и как они хранятся в программах
- Строковые типы
- Двоичные строки
- Текстовые и бинарные типы
- Составные типы
- 3. Строки, выделенные с помощью конструктора
- 5. Ручная Стажировка
- 4. Строковый литерал против строкового объекта
- 7. Производительность и оптимизация
- Переменные в C++
- 6. Сбор Мусора
- 2. Интернирование строк
- Допустимые имена для переменных
Что такое данные и как они хранятся в программах
Все программы работают с данными. Данные — это любое значение, используемое в работе программы: строки, числа, ссылки и символы. Например: имя, возраст, сумма счета, здоровье персонажа в игре и так далее. Отсутствие данных — это тоже данные.
Евгений Кучерявый
Пишет о программировании, в свободное время создает игры. Мечтает открыть собственную студию и выпустить ламповые ролевые игры.
class = «stk-reset stk-theme_26309__separator_divider-1551375397566»>
Все эти и другие значения хранятся в оперативной памяти. Для каждого значения выделяется отдельная ячейка, при этом она может содержать только одно значение.
Давайте посмотрим на это на примере ящиков:
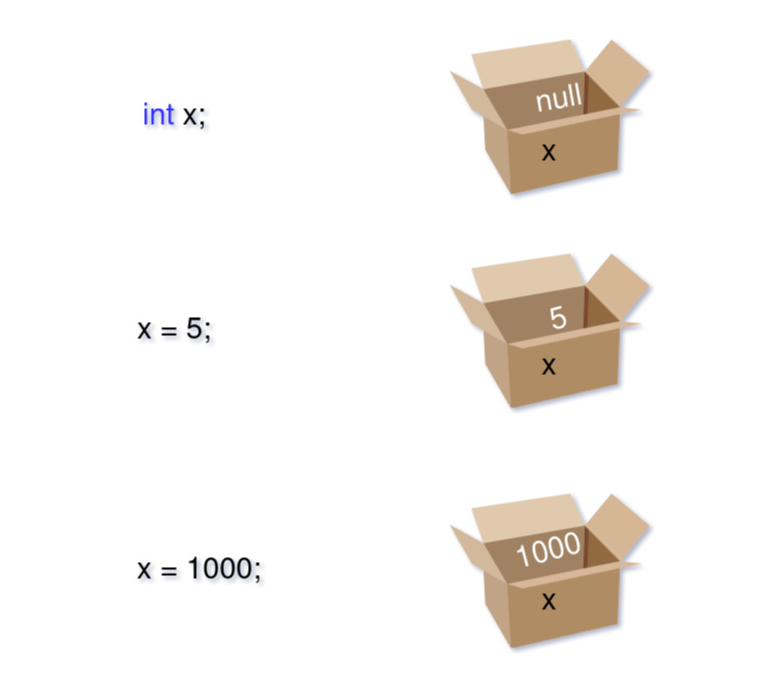
Мы говорим компьютеру, что нам нужен ящик x, в котором хранятся целые числа, но пока не даем ему никакого значения. Компьютер создает такой ящик, подписывает его и вставляет в него нуль.
Далее мы пишем команду x = 5, и компьютер меняет значение внутри поля. Это не меняет размер коробки. Это происходит потому, что для хранения каждого типа примитивных данных выделяется определенный объем памяти. Например, для целых чисел это четыре байта, которые позволяют хранить значения в диапазоне от -2 147 483 648 до 2 147 483 647.
Описанные выше блоки в программировании называются переменными. Их значение можно изменить во время работы программы. Также есть блоки, которые нельзя изменить: они называются константами.
Данные, хранящиеся в настоящее время в памяти, называются состоянием. Программа, система, компьютер и т.д. Могут иметь состояние. В C ++ очень важно иметь доступ к состоянию, чтобы писать полезные программы.
Строковые типы
В типах CHAR и VARCHAR строки обрабатываются как последовательности символов, поэтому при использовании многобайтовых кодировок, таких как UNICODE, размер строки в байтах будет больше, чем в символах.
- VARCHAR (N) — хранит символьные строки переменной длины и является наиболее распространенным строковым типом данных. Значение N может находиться в диапазоне от 0 до 65535 (до MySQL 5.0.3 значение N могло находиться в диапазоне от 0 до 255). Строки этого типа могут занимать меньше места, чем строки CHAR фиксированной длины. Это связано с тем, что VARCHAR использует только реально необходимое пространство (за исключением таблиц с фиксированными размерами строк). Тип VARCHAR использует дополнительный один или два байта для хранения длины строки: один байт, если максимальная длина строки в столбце не превышает 255 байтов, и два байта для более длинных строк. Тип VARCHAR (10) может иметь длину до 11 байтов. Типу VARCHAR (1000) требуется до 1002 байтов, потому что в этом случае для хранения информации о длине строки требуется два байта. VARCHAR повышает производительность за счет использования меньшего дискового пространства. Однако, поскольку строки имеют переменную длину, они могут увеличиваться по мере обновления, вызывая дополнительные накладные расходы. Если строка становится длиннее и больше не умещается в ранее выделенном пространстве, ее дальнейшее поведение зависит от подсистемы хранения. Обычно имеет смысл использовать тип VARCHAR, если выполняется хотя бы одно из следующих условий: максимальная длина строки в столбце значительно больше средней; обновления полей редки, поэтому фрагментация не является проблемой; или используется сложная кодировка, такая как UTF-8, которая использует переменное количество байтов для хранения символа.
- CHAR (N) — имеет фиксированную длину от 0 до 255 байт. При сохранении коротких значений CHAR они дополняются справа пробелами указанной длины. Тип CHAR полезен, когда вам нужно хранить очень короткие строки или когда все значения имеют примерно одинаковую длину. Например, CHAR — хороший выбор для хранения сверток паролей пользователей MD5, которые всегда имеют одинаковую длину. CHAR также имеет приоритет над VARCHAR для данных, которые часто меняются, поскольку строка фиксированной длины не фрагментируется. CHAR также более эффективен, чем VARCHAR для очень коротких столбцов.
При создании таблицы нельзя комбинировать столбцы CHAR и VARCHAR. Если это произойдет, MySQL изменит столбцы CHAR на VARCHAR.
Представьте, что строковый тип используется для хранения значений Y и N. В случае использования CHAR (1) значение будет занимать один байт, а для типа VARCHAR (1) оно будет занимать два байта из-за того, что байтов больше чем длина строки.
Примеры
Значение CHAR (4) Требуется место для хранения VARCHAR (4) Требуется место для хранения
| » | ‘ ‘ | 4 байта | » | 1 байт |
| ‘ab’ | ‘ab ‘ | 4 байта | ‘ab’ | 3 байта |
| ‘abc’ | ‘abc’ | 4 байта | ‘abc’ | 5 байтов |
| ‘abcdefgh’ | ‘abc’ | 4 байта | ‘abc’ | 5 байтов |
Двоичные строки
Для совместимости с предыдущими версиями MySQL были введены два специальных типа данных, BINARY и VARBINARY, которые эквивалентны CHAR и VARHAR, но обрабатывают строку как последовательность байтов, а не как символы. Строки BINARY не имеют кодировок и упорядочены как обычные последовательности байтов. Эти типы могут быть полезны, когда вам нужно хранить двоичные данные и вы хотите, чтобы MySQL сравнивал значение в байтах, а не в символах. В то же время двоичное сравнение может быть намного проще и быстрее символьного.
- VARBINARY — хранит двоичные строки переменной длины.
- BINARY — хранит двоичные строки фиксированной длины.
Текстовые и бинарные типы
Предназначен для хранения больших объемов двоичных или символьных данных.
MySQL обрабатывает значения BLOB и TEXT как отдельные объекты. Единственное различие между семействами BLOB и TEXT состоит в том, что типы BLOB хранят двоичные данные независимо от сортировки и кодирования, тогда как типы TEXT имеют сопоставление и кодировку, связанные с ними.
Семейство TEXT используется для непосредственного хранения текста:
- ТЕКСТ (синоним МАЛЕНЬКИЙ ТЕКСТ)
- TINYTEXT
- СРЕДНИЙ ТЕКСТ
- ДЛИННЫЙ ТЕКСТ
Семейство BLOB — для хранения изображений, звуков, электронных документов и т.д.:
- BLOB (синоним SMALLBLOB)
- TINYBLOB
- СРЕДНИЙ БЛОК
- LONGBLOB
MySQL не может полностью индексировать эти типы данных и не может использовать индексы для сортировки.
Подсистема хранения в памяти не поддерживает типы BLOB и TEXT.
Типы данных Максимальный размер. Байт
| TINYTEXT или TINYBLOB | 28-1 | 255 |
| ТЕКСТ или BLOB | 216-1 (64К-1) | 65535 |
| MEDIUMTEXT или MEDIUMBLOB | 224-1 (16М-1) | 16777215 |
| LONGTEXT или LONGBLOB | 232-1 (4G-1) | 4294967295 |
Составные типы
- ENUM (‘значение1’, ‘значение2’,…, ‘значениеN’) — строки этого типа могут принимать только одно из значений указанного набора. Можно сохранить до 65 535 различных строковых значений. MySQL хранит их очень компактно, группируя их в 1 или 2 байта, в зависимости от количества значений в списке. MySQL обрабатывает каждое значение как целое число, представляющее позицию значения в списке значений поля, и сохраняет отдельную «таблицу поиска» в файле frm, которая определяет соответствие между числом и строкой. Поля типа ENUM сортируются по внутренним целочисленным значениям, а не по самим строкам. Основным недостатком столбцов ENUM является то, что список строк фиксирован, и вы должны использовать команду ALTER TABLE, чтобы добавить или удалить их. Этот тип данных полезен, если вы хотите сохранить выбор из списка или ответ на вопрос в столбце.
- SET (‘значение1’, ‘значение2’,…, ‘значениеN’) — строки этого типа могут принимать любые или все элементы из указанных установленных значений. Обычно при поиске столбцов SET индексы не используются. Можно сохранить до 64 различных строковых значений. Он может занимать до 8 байт, в зависимости от количества значений в списке.
3. Строки, выделенные с помощью конструктора
Когда мы создаем строку с помощью оператора new, компилятор Java создаст новый объект и сохранит его в пространстве кучи, зарезервированном для JVM.
Каждая строка | созданный таким образом будет указывать на другую ячейку памяти со своим собственным адресом.
Посмотрим, чем это отличается от предыдущего случая:
String ConstantString = «Baeldung»; Строка newString = новая строка («Baeldung»); assertThat (constantString) .isNotSameAs (newString);
5. Ручная Стажировка
Мы можем вручную вставить строку в пул строк Java, вызвав метод intern () для объекта, который мы хотим интернировать.
Интернирование струн вручную | сохранит свою ссылку в пуле, и JVM вернет эту ссылку по мере необходимости.
Создадим для этого тестовый пример:
String ConstantString = «Интернированный Baeldung»; Строка newString = новая строка («Интернированный Baeldung»); assertThat (constantString) .isNotSameAs (newString); StringinteredString = newString.intern (); assertThat (constantString) .isSameAs (internedString);
4. Строковый литерал против строкового объекта
Когда мы создаем объект String с помощью оператора new (), он всегда создает новый объект в памяти кучи. С другой стороны, если мы создаем объект, используя синтаксис Stringliteral, такой как «Baeldung», он может вернуть существующий объект из пула строк, если он уже существует. В противном случае он создаст новый строковый объект и поместит его в пул строк для последующего повторного использования.
На высоком уровне оба являются объектами String, но главное отличие состоит в том, что оператор new () всегда создает новый объект String. Кроме того, когда мы создаем строку с использованием литерала, она интернируется.
Это станет намного яснее, если мы сравним два объекта String, созданные с помощью литерала String и оператора new:
Первая строка = «Baeldung»; Вторая строка = «Baeldung»; System.out.println (первый == второй); // Правда
В этом примере объекты String будут использовать одну и ту же ссылку.
Итак, давайте создадим два разных объекта с помощью new и проверим, что у них разные ссылки:
Третья строка = новая строка («Baeldung»); Четвертая строка = новая строка («Baeldung»); System.out.println (третий == четвертый); // Ложь
Точно так же, когда мы сравниваем литерал String с объектом String, созданным с помощью оператора new (), он возвращает false:
Пятая строка = «Baeldung»; Шестая строка = новая строка («Baeldung»); System.out.println (пятый == шестой); // Ложь
В общем, по возможности следует использовать нотацию строкового литерала. Его легче читать, и он дает компилятору возможность оптимизировать наш код.
7. Производительность и оптимизация
В Java 6 единственная оптимизация, которую мы можем сделать, — это увеличить пространство PermGen при вызове программы с использованием параметра MaxPermSize JVM:
-XX: MaxPermSize = 1 ГБ
В Java 7 у нас есть более подробные параметры для изучения и увеличения / уменьшения размера пула. Рассмотрим два варианта просмотра размеров бассейна:
-XX: + PrintFlagsFinal-XX: + PrintStringTableStatistics
Если мы хотим увеличить размер пула с точки зрения сегментов, мы можем использовать параметр StringTableSize JVM:
-XX: StringTableSize = 4901
До Java 7u40 размер пула по умолчанию составлял 1009 сегментов, но это значение было несколько изменено в более поздних версиях Java. Если быть точным, размер пула по умолчанию с Java 7u40 на Java 11 был 60013, а теперь он увеличился до 65536.
Обратите внимание, что увеличение размера пула потребляет больше памяти, но имеет то преимущество, что сокращается время, необходимое для вставки строки в таблицу.
Переменные в C++
Теперь попробуем создать наши переменные.
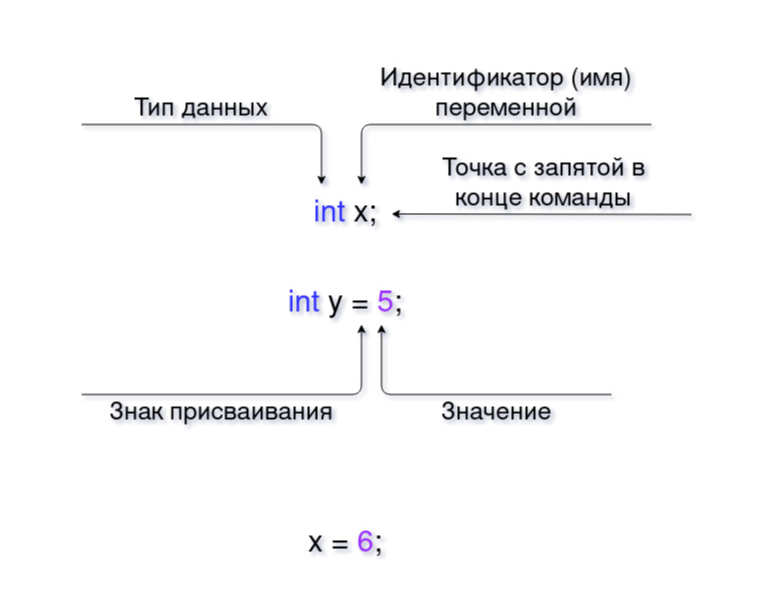
Сначала мы объявляем переменную, то есть сообщаем компьютеру, что нам нужно занять место в памяти. Для этого мы укажем тип данных и, следовательно, имя переменной.
Код Как читать
| целое число x; | Объявляет целочисленную переменную x без значения. |
Это создает переменную без значения. Если вы хотите, чтобы он содержал сразу одно число, вы должны использовать знак присвоения (=):
Код Как читать
| int y = 5; | Объявляет целочисленную переменную y со значением 5. |
Теперь вы можете в любой момент изменить значения переменных:
Код Как читать
| х = 6; | Установите переменную x равной 6. |
Математический знак равенства (=) в программировании называется знаком присваивания.
Важно! Вам просто нужно указать тип данных при объявлении переменной.
Попробуем вывести на экран значение какой-либо переменной. Для этого напишите следующий код:
#включатьintmain () {int age = 21; std :: cout << «Ваш возраст»; std :: cout << возраст; std :: cout << » n»; }
Внимательно прочтите этот код, затем скомпилируйте и запустите программу:
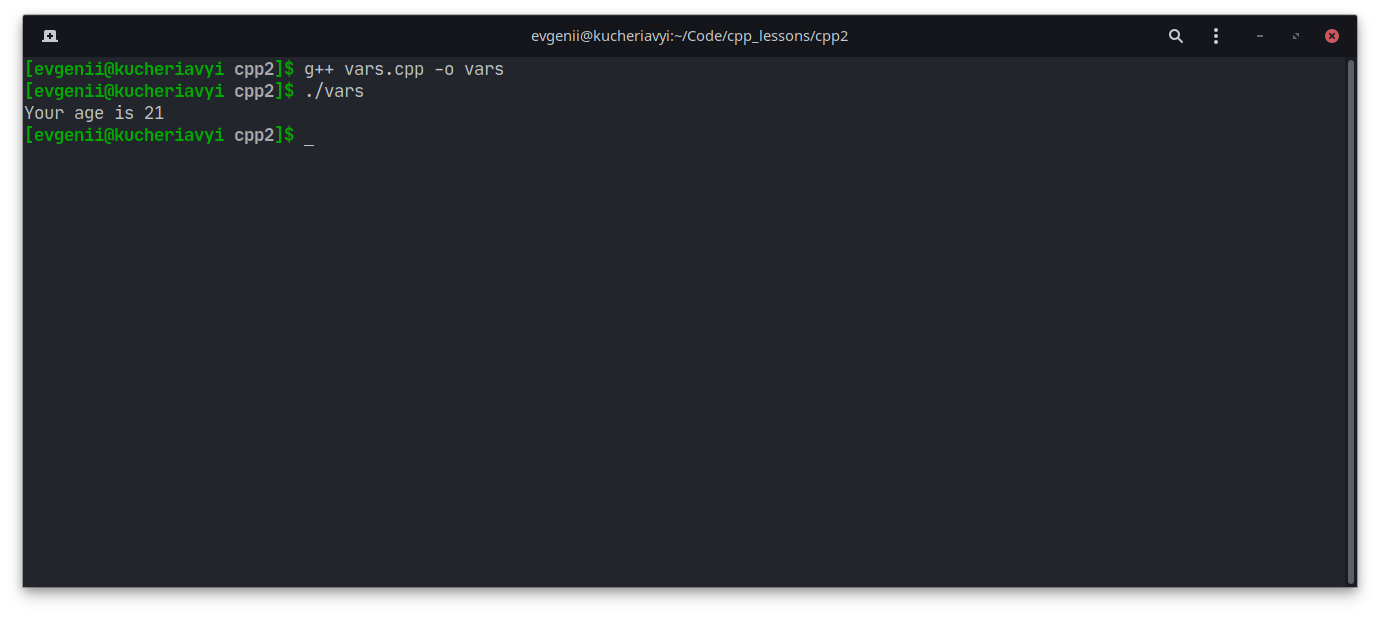
Попробуйте изменить значение переменной age на любое другое число и посмотрите, как изменится результат.
6. Сбор Мусора
До Java 7 JVM помещала пул строк Java в пространство PermGen, которое имеет фиксированный размер: он не может быть расширен во время выполнения и не подходит для сборки мусора .
Риск помещения строк в PermGen (вместо кучи) заключается в том, что мы можем получить ошибку OutOfMemory от JVM, если мы интернируем слишком много строк .
Начиная с Java 7, пул строк Java хранится в пространстве кучи, которое собирается JVM. Преимущество этого подхода заключается в снижении риска ошибки OutOfMemory, поскольку несвязанные строки будут удалены из пула, освобождая таким образом память.
2. Интернирование строк
Из-за неизменности строк в Java JVM может оптимизировать объем выделяемой ей памяти, сохраняя только одну копию каждого строкового литерала в пуле. Этот процесс называется интернированием .
Когда мы создаем переменную String и присваиваем ей значение, JVM ищет в пуле String равное значение.
В случае обнаружения компилятор Java просто вернет ссылку на свой адрес памяти без выделения дополнительной памяти.
Если он не найден, он будет добавлен в (интернет) пул, и его ссылка будет возвращена.
Напишем небольшой тест, чтобы убедиться в этом:
Строка constantString1 = «Baeldung»; Строка constantString2 = «Baeldung»; assertThat (constantString1) .isSameAs (constantString2);
Допустимые имена для переменных
Идентификаторы переменных могут содержать:
- письма;
- числа;
- подчеркивать.
В этом случае имя не может начинаться с цифр. Примеры названий:
- возраст;
- имя;
- _sum;
- имя;
- а_5.
<li>a1; <li>a2;
Все идентификаторы чувствительны к регистру. Это означает, что Имя и Имя — разные переменные.
Рекомендуется давать простые имена на английском языке, чтобы код был понятен и вам, и другим людям. Например:
- цена, а не стоимость;
- iDcurrent, а не pupa;
- carsCount, а не волчица и тд.
Если имя должно состоять из нескольких слов, мы рекомендуем использовать camelCase (от английского «camel case»): первое слово пишется строчной буквой, а каждое последующее слово — прописной.